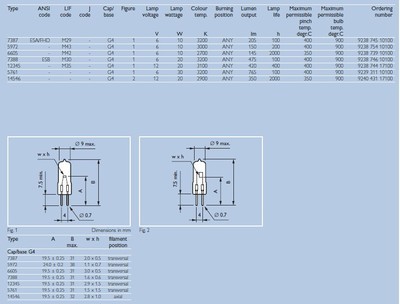
高性能計算環境下復雜深度學習離線訓練的數據處理服務
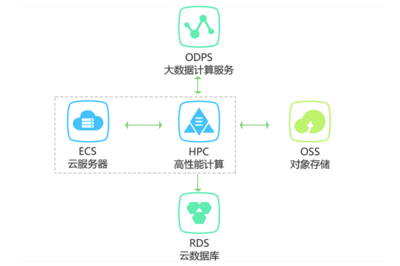
在高性能計算(HPC)環境中,復雜深度學習模型的離線訓練對數據處理服務提出了極高要求。這些服務負責高效、可靠地準備和管理海量數據,確保訓練過程的穩定與模型性能的優化。以下介紹幾種關鍵的數據處理服務及其在高性能深度學習訓練中的應用。
1. 分布式數據存儲與管理
高性能計算系統通常采用分布式文件系統(如Lustre、GPFS)或對象存儲(如Ceph)來管理大規模數據集。這些系統支持并行讀寫,能夠快速加載TB甚至PB級數據,滿足多節點訓練時的數據訪問需求。數據處理服務負責數據的組織、索引和備份,確保數據可用性與完整性。
2. 數據預處理與增強
離線訓練前,原始數據需經過清洗、歸一化、標注和增強等處理。在高性能計算環境中,數據處理服務利用并行計算框架(如Apache Spark、Dask)或專用GPU加速庫(如NVIDIA DALI)實現高效預處理。例如,圖像數據可通過隨機裁剪、旋轉和顏色變換進行增強,提升模型泛化能力;文本數據則需進行分詞、向量化等操作。
3. 數據流水線優化
為減少訓練過程中的I/O瓶頸,數據處理服務構建高效的數據流水線,實現數據加載與模型訓練的異步并行。工具如TensorFlow的tf.data或PyTorch的DataLoader支持數據預取和緩存,將處理后的數據直接送入GPU內存。在高性能計算集群中,流水線還可結合MPI或NCCL實現跨節點數據分發,進一步提升吞吐量。
4. 數據版本控制與元數據管理
復雜深度學習項目常涉及多次實驗和數據集迭代。數據處理服務集成版本控制系統(如DVC)和元數據管理工具(如ML Metadata),跟蹤數據來源、處理歷史及版本變化。這有助于重現訓練結果,優化數據策略,并符合科研或工業場景的合規要求。
5. 容錯與彈性處理
高性能計算環境可能因節點故障或網絡問題導致訓練中斷。數據處理服務需具備容錯機制,例如通過檢查點(Checkpointing)保存中間狀態,或使用彈性數據存儲(如Alluxio)保證數據可恢復性。服務應支持動態擴縮容,以適應計算資源的變化。
6. 異構數據支持與跨格式轉換
深度學習應用常涉及多模態數據(如圖像、文本、視頻)。數據處理服務需支持異構數據的統一管理,并提供格式轉換工具(如將RAW圖像轉為TFRecord或HDF5),優化存儲效率與讀取速度。在高性能計算系統中,這可結合高速網絡(如InfiniBand)實現低延遲數據傳輸。
7. 數據安全與隱私保護
針對敏感數據(如醫療或金融信息),數據處理服務集成加密、訪問控制和匿名化技術。例如,使用同態加密或差分隱私方法在訓練過程中保護數據隱私,同時符合GDPR等法規要求。
高性能計算下的深度學習離線訓練依賴于高度優化的數據處理服務。這些服務通過分布式存儲、并行預處理、流水線優化和容錯機制,有效解決了海量數據管理的挑戰,為復雜模型的訓練提供堅實基礎。隨著AI與HPC的深度融合,數據處理服務將進一步向自動化、智能化和可持續化方向發展。
如若轉載,請注明出處:http://www.vlij.cn/product/19.html
更新時間:2026-03-19 10:05:33